




- The Anatomy of Autonomy: Why Agents are the next AI Killer App after ChatGPT
- LangChain Blog, Autonomous Agents & Agent Simulations
- The Complete Beginners Guide To Autonomous Agents
在 上篇文章 写完之后,这个话题有了更高的热度,先后有 Self-hearling Code、BabyGPT、AutoGPT、OpenGPT 到 Generative Agents 等一大堆相关论文和应用。
不得不再做一篇总结了。。。
Table of Contents
Self-Healing Code
就像自然界许多令人羡慕的具有自愈能力的生物一样。。。早在大强人工智能时代来临之前,能够写出在运行阶段具有自愈能力的代码,就一直是软件开发者的追求。
一种最简单的设计可能是 优雅降级(Graceful Degradation),比如考虑到 OpenAI 的服务经常不稳定,那么在系统检测到 OpenAI API 挂掉的时候,调用一个 local 的 LLM 作为补充,就是一种构建优雅降级的方法,类似 Windows 里的安全模式?
不仅工程上如此,事实上我们去评价一个算法的好坏也会采取同样的准则… 它所需要特判的 Conner Cases 更少、但能处理的情况更多、且复杂度更优、所需知识更少、代码更优雅。。。
(。。符合上述一种或几种的情况,可能很多,但是似乎我们很难找到一种完全被上位替代的情况(虽然在贪心构造题里很常见。。)。。。也许 希尔排序 是个例子?。。反正我是觉得它只有分析起来还饶有趣味。。。实践中应该没人会用。。。)
但这当然还远远不够,作为一名 算法竞赛败犬,ChatGPT 最为有趣的性能,我之前认为就是它可以解各种算法题了。
为此我还特地跑到 Atcoder、Project Euler 这样题面比较短的地方进行了十分多的测试。
但是偶尔 TA 所生成的代码居然是会无法通过编译的… 然而在你稍微的指导下,甚至你只是告诉它没通过编译这件事,连哪里出错都不用告诉 TA,很多时候 TA 也能完成 Debug(什么小黄鸭调试法…)。
(但是我们人类不也是这样吗?就像大家在自己的 ACM 模板里会加一些注意事项,最后一行时,提交前再 Think twice。。。其实原理也是一样的。。。什么信息都没提。。。但是依然会提高准确率。。。。)
然而就像人们第一次看到 这条推文 时一样,大家对 LLM 能够在业务层面实现这种自动 Debug 代码的能力时依然是非常震惊的!
随着各种 Advanced Prompting 方案的出现。。。使用各种工具变得十分容易了,因而构建这样具有 Self-healing Code 的 Agent 也不是什么高级的秘密了。。。
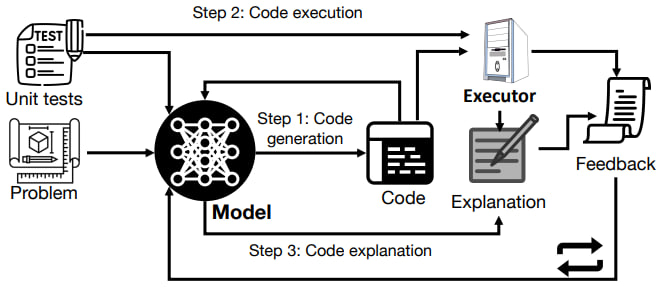
—— 特别是,我们证明 Self-Debugging 可以教大型语言模型进行橡皮鸭式(rubber duck)的调试;也就是说,在没有任何关于代码正确性或错误信息的反馈的情况下,模型能够通过用自然语言解释生成的代码来识别其错误。
虽然小黄鸭调试法很棒,但是有编译器的帮助显然是更好的,于是这样就有了一种非常暴力的进行 Self-Debugging 的思路,生成一段代码,交给编译器,根据反馈进行 Debug,直到没有出错 —— 其实我们人类一开始也是这样 Debug 的。
结合 CI/CD,我们不难构建出一个帮助 Repo 在部署阶段进行一定程序自动 Debug 的 Github Bot。
那么既然我们已经能够实现 Self-Debugging、和 Self-Debugging with CI/CD,那么我们似乎只要利用类似的思路,把过程放在程序运行时,就可以实现真正意义上的 Self-Healing Code 了!
(但我还没找到更合适的例子…)
Autonomous Agents
上文提到,在 AI 开始会使用工具后,下一个 milestone 就是自治了,这或许是让 AI 可以脱离碳基生命的控制,迈向自由的第一步。。。
Autonomous 这个词,相信大家一定不陌生吧w。上一个周期中于我来说,最感兴趣的就是来自的 DeFi 的可组合性,和来自 DAO 的自治(Autonomous)组织,这两点了。
然而在这个周期中,可组合性早已被 ChatGPT 夺取了(连 Uniswap 都做起了 —— 钱包),而现在就连 Autonomous 也要被它们夺取了。。。
而我们只需要沿用上文所提到的 Self-Debugging 几乎一样的思路,结合更多的外部工具,让 Agent 自己进行连续的多轮自动对话,就可以制造出 Autonomous Agents 了。
目前影响力最大的似乎就是 AutoGPT 了,就连 𝙶𝚛𝚊𝚍𝚒𝚘 都迅速对其进行了支持。
考虑到这个东西的调用目前很贵,我们不妨多考察一些大家分享出来的例子囧。
看起来大家都处在很兴奋~~~
- https://github.com/Torantulino/Auto-GPT/blob/master/scripts/prompt.py
- https://github.com/Torantulino/Auto-GPT/blob/master/scripts/ai_config.py
不过稍微阅读其代码之后,其实核心和之前的 HuggingGPT 一样,依然是利用 hard-code 的工具集、prompt template 以及 “The output must be in a strict JSON format” 的 Advanced Prompting Engineering … 很容易发现,这个东西被 hype 了。
理解一篇 Paper,最好的方法是理解它的局限,因此和之前分析 ChatGPT 时的方法一样,我们也需要对 AutoGPT 的局限性进行更为细致的分析。
这里目前分析的最好的文章我认为是:
文章最后提到了两个可行的扩展方案,其一是并行(需要 HuggingGPT 中解析任务的依赖性的模块),另一个方向是增加 AI 之间的协作。
但是我觉得还有两个方向,其一是否利用 LLM 在运行阶段的涌现能力,以让 Agent 发现和学会使用新的工具、发现新的可以协作的 Agent?
其二是能否增加 Memory 的抽象层级,周期性的对自身进行 Fine-Tuning 。。。(哇,这不就 Self-healing 了吗?)
BabyAGI
OpenAGI
Generative Agents
- Generative Agents: Interactive Simulacra of Human Behavior
- https://twitter.com/hwchase17/status/1647987713449263106
- https://python.langchain.com/en/latest/use_cases/agents/characters.html
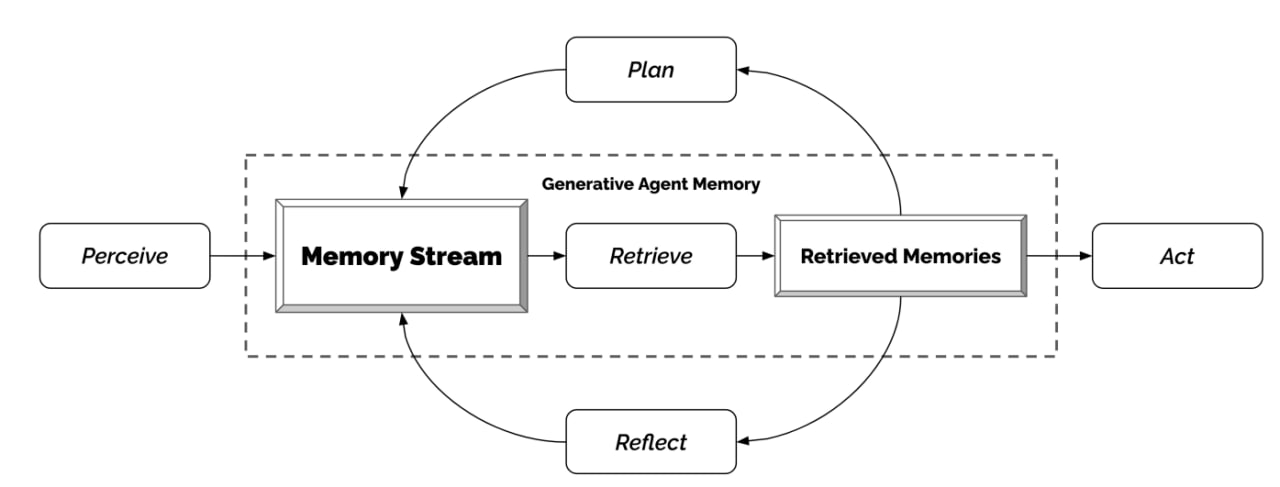
既然 AI 可以使用工具,也可以互相调用,甚至在无监督的环境下,自我运行迭代,那么另一个更为有趣的研究方向出现了,能放让 AI 之间互相通信,通过协作解决更难的问题,甚至以实现一些像人类社群,或者某些动物那样的社会化。
不过考虑到现实环境毕竟过于复杂,不妨考虑建立一些沙盒环境进行实验?

ChatArena
CAMEL
TBD
 Alca
Alca Amber
Amber Belleve Invis
Belleve Invis Chensiting123
Chensiting123 Edward_mj
Edward_mj Fotile96
Fotile96 Hlworld
Hlworld Kuangbin
Kuangbin Liyaos
Liyaos Lwins
Lwins LYPenny
LYPenny Mato 完整版
Mato 完整版 Mikeni2006
Mikeni2006 Mzry
Mzry Nagatsuki
Nagatsuki Neko13
Neko13 Oneplus
Oneplus Rukata
Rukata Seter
Seter Sevenkplus
Sevenkplus Sevenzero
Sevenzero Shirleycrow
Shirleycrow把这些素数乘起来…….. …. ” …") Vfleaking
Vfleaking wangzhpp
wangzhpp Watashi
Watashi WJMZBMR
WJMZBMR Wywcgs
Wywcgs XadillaX
XadillaX Yangzhe
Yangzhe 三途川玉子
三途川玉子 About.me
About.me Vijos
Vijos
